* 혼자공부하는 머신러닝 + 딥러닝 책의 Youtube 강의를 보며 실습 및 공부한 내용입니다.
Chapter 05 트리 알고리즘
05 -1 결정 트리
목적: 결정 트리 알고리즘을 사용해 새로운 분류 문제를 다루어 봅니다. 결정 트리가 머신러닝 문제를 어떻게 해결하는지 이해합니다.
핵심 키워드: 결정 트리, 불순도, 정보 이득, 가지치기, 특성 중요도
책 220p 시작하기 전 에피소드
-> 한빛 마켓에서 신상품으로 와인을 판매하려 한다. 캔와인인데 레드 와인과 화이트 와인 표시가 누락되었다. 캔에 인쇄된 알코올 도수, 당도, PH 값으로 와인 종류 구별할 수 있는 방법이 있을까? 이 3가지 값에 로지스틱 회귀 모델을 적용해보기로 했다.
화이트 와인이 양성 클래스로 값은 1이다. 레드 와인은 음성 클래스로 값 0

판다스 데이터프레임의 유용한 메서드 2개
-> info() 메서드: 데이터프레임의 각 열의 데이터 타입과 누락된 데이터가 있는지 확인하는 데 유용하다.

누락된 값도 없는 것을 확인 가능하다.
+만약 누락된 값이 있다면? 그 데이터를 버리거나 평균값으로 채운 후 사용할 수 있다. 어떤 방식이 최선인지는 미리 알기 어려움. 잊지 않아야 할 점은 훈련 세트의 평균값으로 테스트 세트의 누락된 값을 채워야 한다.
-> describe () 메서드: 열에 대한 간략한 통계를 출력해 준다. 최소, 최대, 평균값 등을 볼 수 있다.
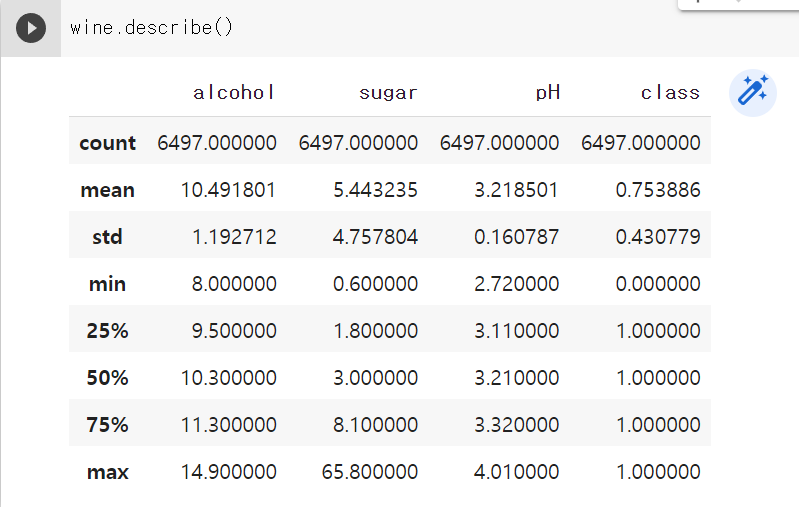
중간값(2사분위수, 50%)과 1사분위수(25%), 3사분위수(75%)도 알려 준다.
그런데 알코올 도수와 당도, pH 값의 스케일이 다른 것을 min과 max를 통해 알 수 있다.
사이킷런의 StandardScaler 클래스를 사용해 특성을 표준화하자.



결과를 보니 점수가 그리 높지 않아 모델이 다소 과소적합된 것 같다.

위의 정보로 상부에 보고할 와인 분류에 대한 보고서를 작성했다.

하지만 잘 이해하기 어렵다. 알코올 도수와 당도가 높을 수록 화이트 와인일 가능성이 높은 것 같다. pH 가 높으면 레드 와인일 가능성이 높다. 더 쉽게 이해할 수 있게 나타내는 방법은 없을까?
결정 트리
-> 스무고개처럼 질문을 하나씩 던져서 정답을 맞춰가는 것
-> 사이킷런은 결정 트리 알고리즘을 제공한다.
-> DecisionTreeClassifier 클래스 사용
-> 사용법은? fit() 메서드를 호출해 모델 훈련 이후 score() 메서드로 정확도 평가
+ 결정 트리 모델을 만들 때 왜 random_state를 지정하나? 책에서는 실습한 결과와 책의 내용이 같도록 유지하기 위해 사용한다. 실전에서는 필요 x

훈련 세트에 대한 점수는 거의 모두 맞춘 수준이라는 것을 알 수 있다.
테스트 세트의 성능은 그에 비해 조금 낮은 걸 보니 과대적합된 모델이라고 볼 수 있다.
이 모델을 그림으로 어떻게 표현할까?
plot_tree() 함수를 사용하면 결정 트리를 이해하기 쉬운 트리 그림으로 출력해준다.

너무 복잡하다. plot_tree() 함수에서 트리의 깊이를 제한하여 출력해보자.


바탕 색이 진할수록 어떤 클래스의 비율이 높다는 뜻이다.
불순도
gini는 지니 불순도를 의미한다. DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 'gini'이다.
지니 불순도 계산법은?
지니 불순도 = 1 - (음성 클래스 비율 제곱 + 양성 클래스 비율 제곱)
지니 불순도는 앞 트리에서 루트 노드가 어떻게 당도 -0.239를 기준으로 나누었는가에 대한 답이 된다.
100개의 샘플이 있는 어떤 노드의 두 클래스의 비율이 정확히 50%라면 지니 불순도는 0.5가 되어 최악이다.
노드에 하나의 클래스만 있다면 지니 불순도는 0이 되어 가장 작다. 이런 노드는 순수 노드라고도 부른다.
결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킨다. 부모 노드와 자식 노드의 불순도 차이를 계산하는 방법은 먼저 자식 노드의 불순도를 샘플 개수에 비례해 모두 더한다. 그다음 부모 노드의 불순도에서 빼면 된다.
예시로 앞의 트리 그림에서 루트 노드를 부모 노드라 하면 왼쪽 노드와 오른쪽 노드가 자식 노드
가 된다. 왼쪽 노드로는 2,922개의 샘플이 이동했고, 오른쪽 노드로는 2,275개의 샘플이 이동했다. 이 때 불순도의 차이는?

이렇게 부모와 자식 노드 사이의 불순도 차이를 정보 이득이라고 부른다.
불순도 기준을 이용해 정보 이득이 최대가 되도록 노드를 분할한다.
아까 테스트 세트에서 점수가 크게 낮았던 점에 대해 다시 다뤄보자.
가지치기
결정 트리도 가지치기를 해야 한다. 가장 간단한 방법은 최대 깊이를 지정하는 것이다.

그 결과 훈련 세트의 성능은 낮아졌지만 테스트 세트의 성능은 거의 그대로이다.
트리 그래프로 그려보자.
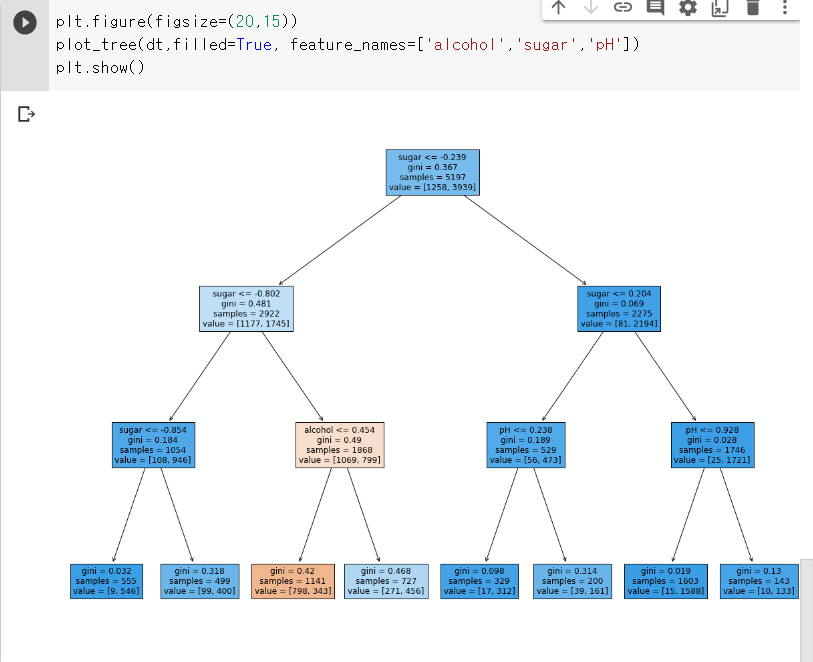
훨씬 보기 좋은 것을 알 수 있다.
세 번째 리프 노드 즉, 깊이 3에 있는 노드 중 왼쪽에서 3번째 노드는 음성 클래스가 더 많은 것을 알 수 있다. 그래서 이 노드에 도착해야만 레드 와인으로 예측한다고 한다. 즉 당도가 0.802보다 크고 -0.239보다 작은와인중에 알코올도수가0.454와같거나작은것이 레드와인이다.
그런데 당도가 음수인 것이 이상하다. 불순도를 기준으로 앞에서 샘플을 나눈다고 했다. 불순도는 클래스별 비율을 가지고 계산하므로 특성값의 스케일은 계산에 영향을 미치지 않는다. 따라서 표준화 전처리를 할 필요가 없다.
그럼 다시 전처리하기 전의 훈련 세트와 테스트 세트로 결정 트리 모델을 다시 훈련해보겠다.

결과가 정확히 같은 것을 알 수 있다.

결과를 보면 색은 같은 트리지만, 특성값을 표준점수로 바꾸지 않아서 당도가 음수가 아니다. 그 결과 이해가 훨씬 쉽다.
다시 레드 와인을 구별해보면 당도가 1.625 보다 크고 4.325보다 작은 와인 중에 알코올 도수가 11.025와 같거나 작은 것이 레드 와인이다.
마지막으로 결정 트리는 어떤 특성이 가장 유용한지 나타내는 특성 중요도를 계산해 주자. 이 트리의 루트 노드와 깊이 1에서 당도를 사용했기 때문에 아마 당도가 가장 유용한 특성 중 하나일 걸로 예측 가능하다. 특성 중요도는 결정 트리 모델의 feature_importances_ 속성에 저장되어 있다. 출력해보자.

알코올 도수, pH 순으로 특성 중요도가 2,3번째로 높다. 이 값을 모두 더하면 1이다.
특성 중요도는 각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산한다.
결론
결정 트리는 비교적 비전문가에게도 설명하기 쉬운 모델을 만든다. 또한, 많은 앙상블 학습 알고리즘의 기반이 된다.
'Personal > AI, Big Data' 카테고리의 다른 글
| 혼공머신 13강 - 트리의 앙상블 (0) | 2022.08.04 |
|---|---|
| 혼공머신 12강 - 교차 검증과 그리드 서치 (0) | 2022.07.21 |
| GAN(Generative Adversarial Networks) 생성적 적대 신경망 (0) | 2022.05.02 |
| 빅데이터 분석기사 필기 - 빅데이터의 이해 (0) | 2021.11.07 |
| [NIPA] 실무 응용 과정 - 03 지도학습 - 회귀 (0) | 2021.10.01 |


