* 혼자공부하는 머신러닝 + 딥러닝 책의 Youtube 강의를 보며 실습 및 공부한 내용입니다.
Chapter 05 트리 알고리즘
05 -2 교차 검증과 그리드 서치
목적: 검증 세트가 필요한 이유를 이해하고 교차 검증에 대해 배웁니다. 그리드 서치와 랜덤 서치를 이용해 최적의 성능을 내는 하이퍼파라미터를 찾습니다.
핵심 키워드: 검증 세트, 교차 검증, 그리드 서치, 랜덤 서치
책 242p 시작하기 전 에피소드
-> 테스트 세트를 사용해 자꾸 성능을 확인하면 점점 테스트 세트에 맞추게 된다. 테스트 세트로 일반화 성능을 올바르게 예측하려면 가능한 한 테스트 세트를 사용하지 말아야 한다. max_depth 매개변수를 사용한 하이퍼파라미터 튜닝을 어떻게 할 수 있을까?
검증 세트
-> 검증 세트: 하이퍼파라미터 튜닝을 위해 모델을 평가할 때, 테스트 세트를 사용하지 않기 위해 훈련 세트에서 다시 떼어 낸 데이터 세트입니다.

+ 테스트 세트와 검증 세트에 얼마나 많은 샘플을 덜어 놔야 하나? 보통 20~30% 훈련 데이터가 아주 많으면 단 몇%만으로도 가능하다.





원래 5,197개였던 훈련 세트가 4,157개로 줄었다. 검증 세트는 1,040개이다.

훈련 세트에 과대적합된 것을 알 수 있다.
결정 트리
-> 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복한다.
-> 이 점수를 평균하여 최종 점수를 얻는다.

+ 3-폴드 교차 검증이란? 훈련 세트를 세 부분으로 나눠서 교차 검증을 수행하는 것을 3-폴드 교차 검증이라고 한다. 훈련 세트를 몇 부분으로 나누냐에 따라 k-폴드 교차 검증 또는 k-겹 교차 검증이라고도 부른다.
-> 보통 5-폴드 교차 검증이나 10-폴드 교차 검증을 많이 사용한다.
-> 이렇게 하면 데이터의 80~90%까지 훈련에 사용할 수 있다.
cross_validate() 함수는 교차 검증 함수로 사이킷런에 있다. 사용법은 먼저 평가할 모델 객체를 첫 번째 매개변수로 전달하고 그 다음 훈련 세트 전체를 전달하면 된다.


fit_time과 score_time은 코랩에서 리소스를 사용하는 상황에 따라 달라질 수 있어서 실습한 값과 책의 값이 다르다.
cross_validate() 함수는 기본적으로 5-폴드 교차 검증을 수행하여 각 키마다 5개의 숫자가 담겨있다. 교차 검증의 최종 점수를 얻어보자. test_score 키에 담긴 5개의 점수를 평균하여 얻을 수 있다.

주의할 점: cross_validate() 는 훈련 세트를 섞어 폴드를 나누지 않는다. 그래서 교차 검증을 할 때 훈련 세트를 섞으려면 분할기를 지정해야 한다. 사이킷런의 분할기는 교차 검증에서 폴드를 어떻게 나눌지 결정해 준다.
cross_validate() 함수는 기본적으로 회귀 모델일 경우 KFold 분할기를 사용하고 분류 모델일 경우 타깃 클래스를 골고루 나누기 위해 StatifiedKFold를 사용한다.


n_splits 매개변수는 몇 폴드 교차 검증을 할지 정한다.
KFold 클래스도 동일한 방식으로 사용할 수 있다.
이제 결정 트리의 매개변수 값을 바꿔가며 가장 좋은 성능이 나오는 모델을 찾아 보자.
테스트 세트를 사용하지 않고 교차 검증을 통해 좋은 모델을 고르면 된다.
하이퍼파라미터 튜닝
머신러닝 모델이 학습하는 파라미터를 모델 파라미터라고 부른다.
모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터를 하이퍼파라미터라고 한다.
사이킷런과 같은 머신러닝 라이브러리를 사용할 때는 모두 클래스나 메서드의 매개변수로 표현되는 것이 하이퍼파라미터.
하이퍼파라미터 튜닝 방법
-> 라이브러리가 제공하는 기본값을 그대로 사용해 모델을 훈련한다.
-> 검증 세트의 점수나 교차 검증을 통해서 매개변수를 조금씩 바꿔 본다.
-> 모델의 매개변수를 바꿔가면서 모델을 훈련하고 교차 검증을 수행해야 한다.
+ 사람의 개입 없이 하이퍼파라미터 튜닝을 자동으로 수행하는 기술은: AutoML
=> 사이킷런에서 제공하는 그리드 서치를 사용한다.
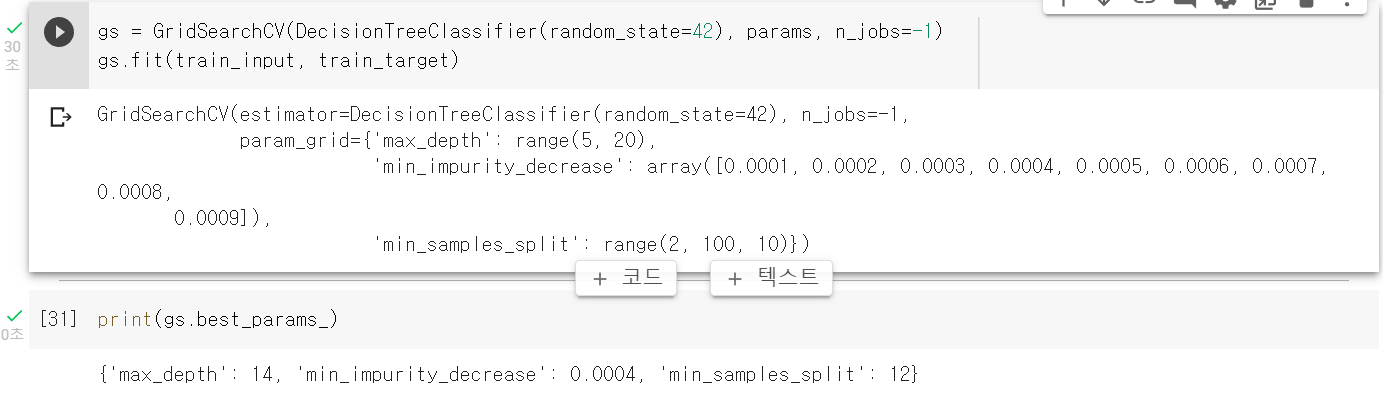
사이킷런의 GridSearchCV 클래스
-> 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행한다.
-> 별도로 cross_validate() 함수를 호출할 필요가 없다.




이 모델을 일반 결정 트리처럼 똑같이 사용할 수 있다.





min一impurity_decrease는 노드를 분할하기 위한 불순도 감소 최소량
max_depth로 트리의 깊이 제한
min_samples_split 노드를 나누기 위한 최소 샘플 수
이 매개변수로 수행할교차 검증 횟수는 9(arrange함수 결과)x15(range함수 결과)x10(range함수 결과)으로 1,350이다. 기본 5-폴드 교차 검증을 수행하므로 6,750의 모델 수가 만들어진다.

랜덤 서치
매개변수의 값이 수치일 때 값의 범위나 간격을 정하기 어려울 수 있다.
또 너무 많은 매개변수 조건이 있어 그리드 서치 수행 시간이 오래 걸릴 수 있다.
위의 2가지 상황에서 랜덤 서치를 사용하면 좋다.
랜덤 서치에는 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달한다.
+싸이파이(scipy) 라이브러리란? 파이썬의 핵심 과학 라이브러리 중 하나로 적분, 보간, 선형 대수, 확률 등을 포함한 수치 계산 전용 라이브러리이다.

uniform과 randint는 주어진 범위에서 고르게 값을 뽑는다. => '균등 분포에서 샘플링한다.'
randint는 정숫값을 uniform은 실숫값을 뽑는다.
randint 객체를 만들고 10개의 숫자를 샘플링해보았다.






결론
검증 세트 여러 번 반복하면 교차 검증 -> 하이퍼파라미터 탐색은 그리드 서치를 사용 -> 매개변수 값이 수치형이고 특히 연속적인 실숫값이면 랜덤 서치 활용
'Personal > AI, Big Data' 카테고리의 다른 글
| 파이썬 기초 라이브러리부터 쌓아가는 머신러닝 3 (0) | 2022.08.21 |
|---|---|
| 혼공머신 13강 - 트리의 앙상블 (0) | 2022.08.04 |
| 혼공머신 11강 - 로지스틱 회귀로 와인 분류하기, 결정 트리 (0) | 2022.07.14 |
| GAN(Generative Adversarial Networks) 생성적 적대 신경망 (0) | 2022.05.02 |
| 빅데이터 분석기사 필기 - 빅데이터의 이해 (0) | 2021.11.07 |


